



Si os acordáis hace una semana os hablé de mi primera araña, [el E-Mail Extractor ese], dije que le faltaba ir profundizando en los enlaces de la pagina. Pues me puse a ello y bueno me parece que ha salido una herramienta muy compatible con la anterior. Aunque da Error cuando intenta abrir una URL inacabada (Error que aún no he podido solucionar.) Si que encuentra y guarda gran parte de las URL de la pagina.

Os dejo el código(se admiten sugerencias xD):
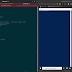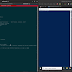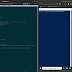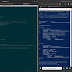
import re
import urllib
web = raw_input("pega aqui la Url: ")
url = []
patron= re.compile('''href=["'](.[^"']+)["']''')
busqueda = re.findall(patron, urllib.urlopen(web).read())
for i in busqueda:
url.append(i)
d1 = str(i)
ListaUrl = open('url.txt','a+')
ListaUrl.write("--> "+ d1 +" <--")
ListaUrl.close()
busqueda2 = re.findall(patron, urllib.urlopen(i).read())
for e in busqueda2:
url.append(e)
d2 = str(e)
ListaUrl = open('url.txt','a+')
ListaUrl.write("--> "+ d2 +" <--")
ListaUrl.close()
print "URls Guardadas con Exito."
Os dejo el enlace a GitHub para que os lo bajéis:
Algunas aplicaciónes que se me ocurren para este programa son muy variadas. Hacen que me plantee crear un buscador o empezar a scanear muchas paginas para hacerme con muchos correos electronicos para un posible mal uso despues. No se, yo me lo he pasado bien intantando lo hacerlo y ahora solo me hace falta arregar ese fallo y juntarlo con el HTML E-Mail Extractor.
Sed Buenos con esto ;)
No hay comentarios:
Publicar un comentario